能用众力,则无敌于天下矣;能用众智,则无畏于圣人矣。
—《三国志·吴志·孙权传》
【引言】
AdaBoosting,是英文”Adaptive Boosting“(自适应增强)的缩写,是一种迭代提升算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
【计算学习理论:霍夫丁不等式(Hoeffding‘s inequality)】
欲统计某个电视节目在全国的收视率,我们不可能去统计整个国家中每个人是否观看该电视节目、进而算出收视率,只能抽样一部分人口,然后将抽样人口中观看该电视节目的比例与抽样人口中观看该电视节目的人口比例作为该电视节目的全国收视率。学者Hoeffding提及了一个理论,全国人口中观看该电视节目的人口比例(记作\(x\))与抽样人口中观看该电视节目的人口比例(记作\(y \))满足如下关系:
\(\begin{align} P(| x – y| > \epsilon) \leq 2e^{-2N\epsilon^2}\end{align}\)
其中:N是采样人口总数;\( \epsilon \in (0,1)\)是所设定的可容忍误差范围。
而当N足够大时,“全国人口中电视节目收视率”与“样本人口中电视节目收视率”差值超过误差范围\(\epsilon\)的概率非常小。
【计算学习理论:概率近似正确(Probably approximately correct, PAC)】
对于统计电视节目收视率这样的任务,我们可以采用不同的采样方法(即不同模型)来计算收视率,但每个模型都会产生不同的误差。那么我们如果得到完成该任务的若干“弱模型”,是否可以将这些弱模型组合起来,形成一个强模型?这是PAC要解决的问题。
在概率近似正确的背景下,有“强可学习模型”和“弱可学习模型”
强可学习模型(strongly learnable)
学习模型能够以较高精度对绝大多数样本完成识别分类任务
弱可学习模型(weakly learnable)
学习模型仅能完成若干部分样本识别与分类,其精度略高于随机猜测
强可学习和弱可学习是等价的
如果已经发现了“弱可学习算法”,那么我们可以将其提升(boosting)为“强可学习算法”。Ada Boosting就是这样的算法,具体而言,Ada Boosting就是将一些列弱分类器组合起来,构成一个强分类器。
【Ada Boosting 核心问题】
-
在每个弱分类器的学习过程中,如何改变训练数据的权重?
提高在上一轮分类错误样本的权重
-
如何将一系列弱分类器组合成强分类器?
通过加权多数表决方法来提高分类误差小的弱分类器权重,让其在最终分类中起到更大的作用。同是减少分类误差搭的弱分类器的权重,让其在最终分类中仅起到较小作用。
【Ada Boosting-数据样本权重初始化】
给定包含N个标注数据的训练集合\(\Gamma, \Gamma=\{(x_1, y_1), \dots (x_N, y_N)\}\)。
其中:\(x_i (i \in [1, N]) \in X \subseteq R^n, y_i \in Y = \{-1,1\} \)
Ada Boosting算法将从这些标注数据出发。其初始化方法如下:
\(D_1 = (W_{11}, \dots, W_{1i}, \dots , W_{1N})\)
其中:\(W_{1i} = \frac{1}{N} \)
【Ada Boosting-训练第m个弱分类器】
对于\(m=1,2,\dots, M\):
a) 使用具有分布权重\(D_m\)的训练数据来学习得到第m个基分类器(弱分类器)\(G_m \):
\(G_m(x): X \to \{-1,1\}\)
b) 计算出\( G_m(x)\)在训练数据集上的分类误差\( err_m\):
\(\begin{align} err_m = \sum_{i=1}^Nw_{mi}I(G_m(x_i) \neq y_i)\end{align}\)
其中:
\(I(\cdot) = \begin{cases} 1 && G_m(x_i) \neq y_i\\ 0 &&otherwise\end{cases}\)
ps.该误差为被错误分类的样本所具有权重的累加。
c) 计算弱分类器\(G_m(x) \)的权重:
\( \alpha_m = \frac{1}{2}\ln \frac{1-err_m}{err_m}\)
ps.
-
当第\(m\)个弱分类器\(G_m(x)\)的错误率为1,即\(\begin{align}err_m = \sum_{i=1}^N w_{mi} I(G_m(x_i) \neq y_i) = 1\end{align}\),意味着每个样本分类都出错,则\(\alpha = \frac{1}{2}\ln \frac{1-err_m}{err_m} \to – \infty\),那么给予第m个弱分类器\(G_m(x)\)的权重就很低。
-
当第m个弱分类器\( G_m(x)错误率为\frac{1}{2}, \alpha_m = \frac{1}{2}\ln \frac{1-err_m}{err_m} = 0\)。如果错误率\(err_m < \frac{1}{2}\),权重\(\alpha\)就为正(\( err_m < \frac{1}{2}, \alpha > 0\))。可知权重随着错误率的减小而增大,即错误率越小的弱分类器会赋予更大权重。
-
如果一个弱分类器的错误率为\(\frac{1}{2}\),可视为其性能仅相当于随机分类效果
d) 更新训练数据的分布权重:
\(\begin{align}D_{m+1} = w_{m+1,i} = \frac{w_{m,i}}{Z_m}e^{-\alpha_my_iG_m(x_i)} \end{align}\)
其中:\( Z_m\)是归一化因子以使得\( D_{m+1}\)为概率分布:
\(\begin{align} Z_m = \sum_{i=1}^{N}w_{m,i} e^{-\alpha_m y_i G_m(x_i)}\end{align}\)
在开始训练第m+1个弱分类器\( G_{m+1}(x)\)之前对训练数据及中数据权重进行调整:
\(w_{m+1, i} = \begin{cases} \frac{w_{m.i}}{Z_m} e^{-\alpha_m} && G_m(x_i) = y_i \\ \frac{w_{m, i}}{Z_m} e^{\alpha_m} && G_m(x_i) \neq y_i\end{cases}\)
-
由此可见,如果某个样本无法被第m个弱分类器\(G_m(x)\)分类成功,则需要增大该样本权重,否则减少该样本权重。这样,被错误分类样本会在训练第m+1个弱分类器\(G_{m+1}(x)\)时会被重点关注。
-
在每一轮学习过程中,Ada Boosting算法均在划重点(重视当前尚未被正确分类的样本)
【Ada Boosting-弱分类器组合成强分类器】
线性加权组合弱分类器\(f(x)\)
\(\begin{align}f(x)=\sum_{i=1}^M\alpha_mG_m(x)\end{align}\)
得到强分类器\(G(x)\)
\(\begin{align}G(x) = sign(f(x)) = sign(\sum_{i=1}^M \alpha _m G_m(x))\end{align}\)
\( f(x)\)是M个弱分类器的加权线性累加,分类能力越强的弱分类器具有更大的权重。
\( \alpha_m\)累加结果并不等于1
\( f(x)\)符号决定样本\( x\)分类为1或-1。如果\(\begin{align}\sum_{i=1}^M\alpha_mG_m(x) \end{align}\)为正,则强分类器\( G(x)\)将样本\(x\)分类为1;否则为-1。
【回顾霍夫丁不等式】
假设有𝑴个弱分类器𝑮𝒎(𝟏 ≤ 𝒎 ≤ 𝑴) , 则𝑴个弱分类器线性组合所产生误差满足如下条件:
\(\begin{align} P(\sum_{i=1}^MG_m(x) \neq \zeta(x) ) \leq e^{\frac{1}{2}M(1-2\epsilon)^2}\end{align}\)
-
𝜁(𝑥) 是真实分类函数、𝜀 ∈ (0,1) 。上式表明,如果所“组合” 弱分类器越多,则学习
分类误差呈指数级下降,直至为零。 -
上述不等式成立有两个前提条件:1) 每个弱分类器产生的误差相互独立; 2) 每个弱分
类器的误差率小于50%。因为每个弱分类器均是在同一个训练集上产生,条件1)难以
满足。也就说,“准确性(对分类结果而言)”和“差异性(对每个弱分类器而言)”
难以同时满足。 -
Ada Boosting 采取了序列化学习机制。
【Ada Boosting- 优化目标】
Ada Boost实际在最小化如下指数损失函数(minimization of exponential loss ):
\(\begin{align} \sum_i e^{-y_if(x_i)}=\sum_ie^{-y_i\sum_{m=1}^{M}\alpha_mG_m(x_i)}\end{align}\)
Ada Boost的分类误差上界如下所示:
\(\begin{align} \frac{1}{N} \sum_{i=1}^N I(G(x_i) \neq y_i) \leq \frac{1}{N}\sum+i e^{-y_if(x_i)} = \prod_mZ_m\end{align}\)
在第𝑚次迭代中,Ada Boosting总是趋向于将具有最小误差的学习模型选做本轮生成
的 弱分类器 𝐺𝑚,使得累积误差快速下降。
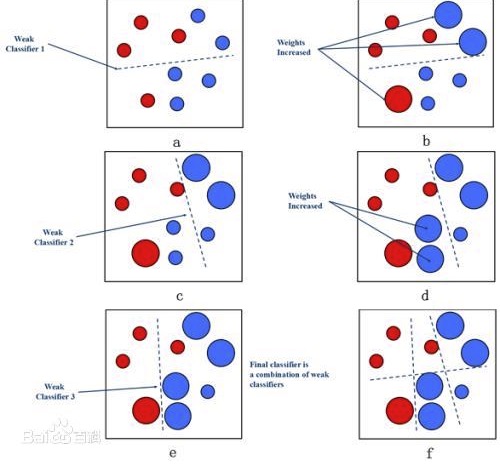
【例子】

【分类与回归的区别】
两者均是学习输入变量和输出变量之间潜在关系模型,基于学习所得模
型将输入变量映射到输出变量。

监督学习分为回归和分类两个类别。
在回归分析中,学习得到一个函数将输入变量映射到连续输出空间,如价格和温度等,即值域是连续空间。
在分类模型中,学习得到一个函数将输入变量映射到离散输出空间,如人脸和汽车等,即值域是离散空间。
【参考文献】
-
人工智能.吴飞.浙江大学计算机学院.中国大学MOOC2020.