凡治众如治寡,分数是也。
孙子兵法
【递归与分治】
直接或间接地调用自身的算法称为递归算法。
用函数自身给出定义的函数称为递归函数。
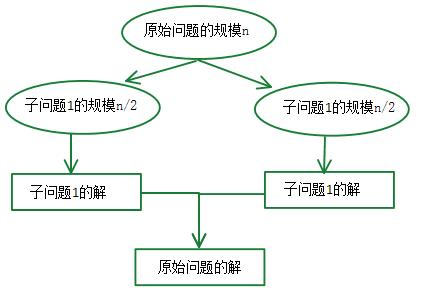
分治与递归
-
由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。
-
在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。这自然导致递归过程的产生。
-
分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。
【递归基本要素】
递归(Recursion)就是子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己, 是一种描述问题和解决问题的基本方法.
递归有两个基本要素:
⑴ 边界条件(递归出口): 确定递归到何时终止;
⑵ 递归模式(递归体): 大问题是如何分解为小问题的.
注意: 边界条件与递归模式是递归函数的二个要素, 递归函数只有具备了这两个要素, 才能在有限次计算后得出结果.
【递归算法的实现】
当一个算法调用另一个算法时,系统需要在运行被调用算法之前完成三件事:
(1) 将所有实参指针、返回地址等信息传递给被调用算法;
(2) 为被调用算法的局部变量分配存储区;
(3) 将控制转移到被调用算法的数据区。
从被调用算法返回调用算法时,系统也相应地要完成三件事:
(1) 保存被调用算法的计算结果;
(2) 释放分配给被调用算法的数据区;
(3) 依照被调用算法保存的返回地址将控制转移到调用算法。
当有多个算法构成嵌套调用时, 按照后调用先返回的原则进行.
算法调用时的信息传递和控制转移都是通过栈来实现的.
即系统将整个程序运行所需的数据空间安排在一个栈中, 每调用一个算法, 就为它在栈顶分配一个存储区, 每退出一个算法, 就释放它在栈顶的存储区.
实现递归调用的关键是为算法建立递归调用工作栈
其工作栈示意图如下:

【小结】
优点: 结构清晰, 可读性强, 而且容易用数学归纳法来证明算法的正确性, 因此它为设计算法、调试程序带来很大方便.
缺点: 递归算法的运行效率较低, 无论是耗费的计算时间还是占用的存储空间都比非递归算法要多.

解决方法: 在递归算法中消除递归调用, 使其转化为非递归算法。
(1) 采用一个用户定义的栈来模拟系统的递归调用工作栈. 该方法通用性强, 但本质上还是递归, 只不过人工做了本来由编译器做的事情, 优化效果不明显.
(2) 用递推来实现递归函数.
(3) 通过Cooper变换、反演变换能将一些递归转化为尾递归, 从而迭代求出结果.
后两种方法在时空复杂度上均有较大改善,但其适用范围有限。
尾递归:
从最后开始计算, 每递归一次就算出相应的结果. 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量. 直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去.(尾递归的支持与编译器有关,有些语言如Java本身是不支持尾递归的)
【参考文献】
-
2019年广西师范大学计算机与信息工程学院算法设计与分析课件[OL].李志欣教授.2019.01.01
[…] 20190304 20190304 […]