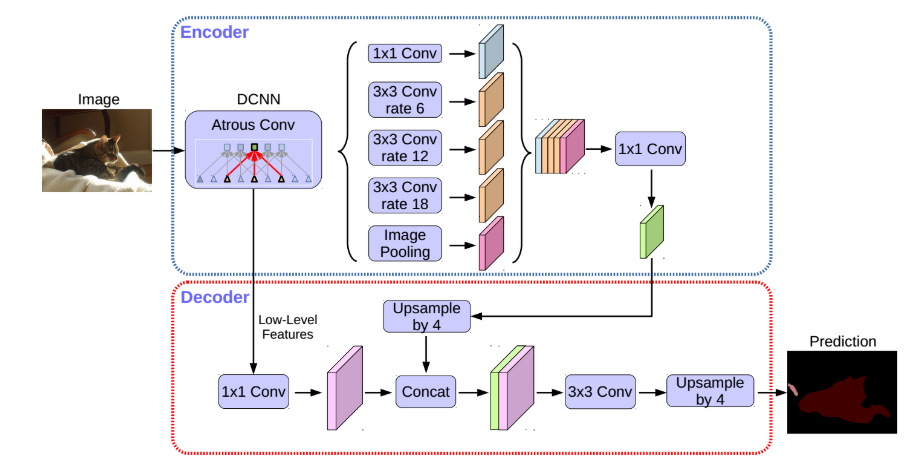
【背景】
空间金字塔池化模块(spatial pyramid pooling,SPP) 和 编码-解码结构(encode-decoder) 用于语义分割的深度网络结构. SPP 利用对多种比例(rates)和多种有效接受野(fields of view)的不同分辨率特征处理,来挖掘多尺度的上下文内容信息. 解编码结构逐步重构空间信息来更好的捕捉物体边界.
DeepLabv3+ 对 DeepLabV3 添加了一个简单有效的解码模块,提升了分割效果,尤其是对物体边界的分割. 基于提出的编码-解码结构,可以任意通过控制 atrous convolution 来输出编码特征的分辨率,来平衡精度和运行时间(已有编码-解码结构不具有该能力.).
DeepLabV3+ 进一步利用 Xception 模块,将深度可分卷积结构(depthwise separable convolution) 用到带孔空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)模块和解码模块中,得到更快速有效的 编码-解码网络.
【实验环境】
-
CUDA: 9.2.148
-
Torch:1.2.0
-
OS: Ubuntu 16.04
-
HW: Nvidia Tesla P100 / Nvidia GTX 1080Ti / Nvidia RTX 2080Ti
【网络结构】

【ResNet】
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题
-
计算资源的消耗
-
模型容易过拟合
-
梯度消失/梯度爆炸问题的产生
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batch Normalization也可以避免。貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。
作者发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
当网络退化时,浅层网络能够达到比深层网络更好的训练效果,这时如果我们把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差,或者说如果一个VGG-100网络在第98层使用的是和VGG-16第14层一模一样的特征,那么VGG-100的效果应该会和VGG-16的效果相同。所以,我们可以在VGG-100的98层和14层之间添加一条直接映射(Identity Mapping)来达到此效果。
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了\(l + 1\)层的网络一定比\(l\)层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
本文不详细对残差网络进行推导与计算,详情点击:
【Basic Block】

一个简单的残差网络块示意图如上,pytorch代码如下:
class BasicBlock(nn.Module): """Basic Block for resnet 18 and resnet 34 """ #BasicBlock and BottleNeck block #have different output size #we use class attribute expansion #to distinct expansion = 1 def __init__(self, in_channels, out_channels, stride=1): super().__init__() #residual function self.residual_function = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels * BasicBlock.expansion) ) #shortcut self.shortcut = nn.Sequential() #the shortcut output dimension is not the same with residual function #use 1*1 convolution to match the dimension if stride != 1 or in_channels != BasicBlock.expansion * out_channels: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(out_channels * BasicBlock.expansion) ) def forward(self, x): return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
【BottleNeck】

BottleNeck示意图如上,代码如下:
class BottleNeck(nn.Module): """Residual block for resnet over 50 layers """ expansion = 4 def __init__(self, in_channels, out_channels, stride=1): super().__init__() self.residual_function = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False), nn.BatchNorm2d(out_channels * BottleNeck.expansion), ) self.shortcut = nn.Sequential() if stride != 1 or in_channels != out_channels * BottleNeck.expansion: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False), nn.BatchNorm2d(out_channels * BottleNeck.expansion) ) def forward(self, x): return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
【ResNet】
ResNet101代码如下:
class Resnet101(nn.Module):
def __init__(self, stride=32, *args, **kwargs):
super(Resnet101, self).__init__()
assert stride in (8, 16, 32)
dils = [1, 1] if stride==32 else [el*(16//stride) for el in (1, 2)]
strds = [2 if el==1 else 1 for el in dils]
self.conv1 = nn.Conv2d(
3,
64,
kernel_size = 7,
stride = 2,
padding = 3,
bias = False)
self.bn1 = BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(
kernel_size = 3,
stride = 2,
padding = 1,
dilation = 1,
ceil_mode = False)
self.layer1 = create_stage(64, 256, 3, stride=1, dilation=1)
self.layer2 = create_stage(256, 512, 4, stride=2, dilation=1)
self.layer3 = create_stage(512, 1024, 23, stride=strds[0], dilation=dils[0])
self.layer4 = create_stage(1024, 2048, 3, stride=strds[1], dilation=dils[1])
self.init_weight()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.maxpool(x)
feat4 = self.layer1(x)
feat8 = self.layer2(feat4)
feat16 = self.layer3(feat8)
feat32 = self.layer4(feat16)
return feat4, feat8, feat16, feat32
def init_weight(self):
state_dict = modelzoo.load_url(resnet101_url)
self_state_dict = self.state_dict()
for k, v in self_state_dict.items():
if k in state_dict.keys():
self_state_dict.update({k: state_dict[k]})
self.load_state_dict(self_state_dict)
def get_params(self):
bn_params = []
non_bn_params = []
for name, param in self.named_parameters():
if 'bn' in name or 'downsample.1' in name:
bn_params.append(param)
else:
non_bn_params.append(param)
return bn_params, non_bn_params
【ASPP】
class ASPP(nn.Module): def __init__(self, in_chan=2048, out_chan=256, with_gp=True, *args, **kwargs): super(ASPP, self).__init__() self.with_gp = with_gp self.conv1 = ConvBNReLU(in_chan, out_chan, ks=1, dilation=1, padding=0) self.conv2 = ConvBNReLU(in_chan, out_chan, ks=3, dilation=6, padding=6) self.conv3 = ConvBNReLU(in_chan, out_chan, ks=3, dilation=12, padding=12) self.conv4 = ConvBNReLU(in_chan, out_chan, ks=3, dilation=18, padding=18) if self.with_gp: self.avg = nn.AdaptiveAvgPool2d((1, 1)) self.conv1x1 = ConvBNReLU(in_chan, out_chan, ks=1) self.conv_out = ConvBNReLU(out_chan*5, out_chan, ks=1) else: self.conv_out = ConvBNReLU(out_chan*4, out_chan, ks=1) self.init_weight() def forward(self, x): H, W = x.size()[2:] feat1 = self.conv1(x) feat2 = self.conv2(x) feat3 = self.conv3(x) feat4 = self.conv4(x) if self.with_gp: avg = self.avg(x) feat5 = self.conv1x1(avg) feat5 = F.interpolate(feat5, (H, W), mode='bilinear', align_corners=True) feat = torch.cat([feat1, feat2, feat3, feat4, feat5], 1) else: feat = torch.cat([feat1, feat2, feat3, feat4], 1) feat = self.conv_out(feat) return feat def init_weight(self): for ly in self.children(): if isinstance(ly, nn.Conv2d): nn.init.kaiming_normal_(ly.weight, a=1) if not ly.bias is None: nn.init.constant_(ly.bias, 0)
【DeepLabv3 basic-ConvBNReLU】
class ConvBNReLU(nn.Module): def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, dilation=1, *args, **kwargs): super(ConvBNReLU, self).__init__() self.conv = nn.Conv2d(in_chan, out_chan, kernel_size = ks, stride = stride, padding = padding, dilation = dilation, bias = True) self.bn = BatchNorm2d(out_chan) self.init_weight() def forward(self, x): x = self.conv(x) x = self.bn(x) return x def init_weight(self): for ly in self.children(): if isinstance(ly, nn.Conv2d): nn.init.kaiming_normal_(ly.weight, a=1) if not ly.bias is None: nn.init.constant_(ly.bias, 0)
【解码器Decoder】
class Decoder(nn.Module): def __init__(self, n_classes, low_chan=256, *args, **kwargs): super(Decoder, self).__init__() self.conv_low = ConvBNReLU(low_chan, 48, ks=1, padding=0) self.conv_cat = nn.Sequential( ConvBNReLU(304, 256, ks=3, padding=1), ConvBNReLU(256, 256, ks=3, padding=1), ) self.conv_out = nn.Conv2d(256, n_classes, kernel_size=1, bias=False) self.init_weight() def forward(self, feat_low, feat_aspp): H, W = feat_low.size()[2:] feat_low = self.conv_low(feat_low) feat_aspp_up = F.interpolate(feat_aspp, (H, W), mode='bilinear', align_corners=True) feat_cat = torch.cat([feat_low, feat_aspp_up], dim=1) feat_out = self.conv_cat(feat_cat) logits = self.conv_out(feat_out) return logits def init_weight(self): for ly in self.children(): if isinstance(ly, nn.Conv2d): nn.init.kaiming_normal_(ly.weight, a=1) if not ly.bias is None: nn.init.constant_(ly.bias, 0)
【整体框架】
class Deeplab_v3plus(nn.Module): def __init__(self, n_classes, aspp_global_feature): super(Deeplab_v3plus, self).__init__() self.backbone = Resnet101(stride=16) self.aspp = ASPP(in_chan=2048, out_chan=256, with_gp=aspp_global_feature) self.decoder = Decoder(n_classes, low_chan=256) # self.backbone = Darknet53(stride=16) # self.aspp = ASPP(in_chan=1024, out_chan=256, with_gp=False) # self.decoder = Decoder(cfg.n_classes, low_chan=128) self.init_weight() def forward(self, x): H, W = x.size()[2:] feat4, _, _, feat32 = self.backbone(x) feat_aspp = self.aspp(feat32) logits = self.decoder(feat4, feat_aspp) logits = F.interpolate(logits, (H, W), mode='bilinear', align_corners=True) return logits def init_weight(self): for ly in self.children(): if isinstance(ly, nn.Conv2d): nn.init.kaiming_normal_(ly.weight, a=1) if not ly.bias is None: nn.init.constant_(ly.bias, 0) def get_params(self): back_bn_params, back_no_bn_params = self.backbone.get_params() tune_wd_params = list(self.aspp.parameters()) \ + list(self.decoder.parameters()) \ + back_no_bn_params no_tune_wd_params = back_bn_params return tune_wd_params, no_tune_wd_params
【网络输出图】
Deeplab_v3plus( (backbone): Resnet101( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer3): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (6): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (7): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (8): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (9): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (10): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (11): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (12): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (13): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (14): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (15): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (16): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (17): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (18): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (19): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (20): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (21): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (22): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer4): Sequential( (0): Bottleneck( (conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) ) (aspp): ASPP( (conv1): ConvBNReLU( (conv): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (conv2): ConvBNReLU( (conv): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (conv3): ConvBNReLU( (conv): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(12, 12), dilation=(12, 12)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (conv4): ConvBNReLU( (conv): Conv2d(2048, 256, kernel_size=(3, 3), stride=(1, 1), padding=(18, 18), dilation=(18, 18)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (conv_out): ConvBNReLU( (conv): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (decoder): Decoder( (conv_low): ConvBNReLU( (conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1)) (bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (conv_cat): Sequential( (0): ConvBNReLU( (conv): Conv2d(304, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): ConvBNReLU( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (conv_out): Conv2d(256, 19, kernel_size=(1, 1), stride=(1, 1), bias=False) ) )
【参考文献】
-
Github:weiaicunzai/Pytorch-cifar100:https://github.com/weiaicunzai/pytorch-cifar100
-
Github:fregu856/deeplabv3:https://github.com/fregu856/deeplabv3
-
Github:mcordts/CityscapesScripts:https://github.com/mcordts/cityscapesScripts
-
论文阅读 – (DeeplabV3+)Encoder-Decoder with Atrous Separable Convolution
【附】
源码Github仓库:https://github.com/Welllee12366/DLFramework