【Backgroud】
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs
【论文提出的方法】
-
用扩张/空洞卷积提取密集特征并增大感受野
-
用ASPP进行多尺度图像表征
-
用全连接条件随机场结构进行边缘修复
【思路】

【Why Is Atrous Convolution?】
作者提到在传统的深层神经网络(DCNN)中连续的最大池化和下采样的重复组合层大大的降低了最终的feature map的空间分辨率,也去除了大量的空间信息。一个补救的方式是使用deconvolutional layer(转置卷积,用于扩大特征映射分辨率),但这需要额外的时间和计算。
于是DeepLab采用扩张卷积用任意特征响应分辨率计算任何层的特征映射。
让我们从直观上理解扩张卷积:
对于一维卷积:
我们让\(y[i]\)表示空洞卷积的输出,输入为\(x[i]\),长度K的卷积核为\( \omega [k]\).则定义如下公式:
\(\begin{align} y[i] = \sum_{k=1}^{K}x[i+r \cdot k] \omega [k]\end{align}\)
输入采样的步长为参数\( r\), 而\( r = 1\)时则表示普通卷积操作。
如下图所示:

图(a)为普通卷积,图(b)为填充率为2的空洞卷积
对于二维卷积见下图:

图中两个分支:
上分支表示为传统卷积,具体操作如下:首先下采样将分辨率降低2倍,做卷积。再上采样得到结果。本质上这只是在原图片的1/4内容上做卷积响应
下分支为填充率为2的空洞卷积。
空洞卷积的优点概括为:虽然有效滤波器的大小增加了,但实际计算参数时只需要考虑非零滤波器值,因此滤波器参数的数目和每个位置的操作数都保持不变。
论文在之后的DCNN上下文中,在某些层灵活地使用空洞卷积,提高了任意分辨率计算DCNN网络响应
为了使VGG-16或ResNet-101网络中计算的特征响应的空间密度增加一倍,我们找到了最后一个降低分辨率(“pool5”或“conv5_1”)的池化或卷积层,将其步长设置为1以避免信号抽取,并将所有后续卷积层替换为 的空洞卷积层。
将这种方法贯穿整个网络,可以让我们在原始图像分辨率下计算特征响应,但这样计算量会太高。我们采用了一种混合的方法,取得了很好的效率/精度折中,使用空洞卷积增加了4倍的计算特征映射的密度,然后以8倍的方式进行快速双线性插值,以恢复原始图像分辨率的特征映射。在此设置中,双线性插值就足够了,因为得到的class score maps(对应于log-probabilities)非常平滑。
与FCN所采用的反卷积方法不同,我们这种方法将图像分类网络直接转换为密集的特征提取器,不需要学习任何额外参数,从而在实践中加快了DCNN的训练速度。
空洞卷积还允许在任何DCNN层任意放大滤波器的视野。最新的DCNN采用小卷积核(通常为3×3),以便降低计算量和控参数数量。比例 的空洞卷积在连续滤波器值之间引入 个0,有效地将一个 的滤波器的核大小扩大到 ,而不增加参数数量或计算量。因此,空洞卷积提供了一种有效的控制视野的机制,并在准确定位(小视野)和上下文空间信息(大视野)之间找到最佳权衡。我们成功地采用了这种技术:我们的DeepLab-LargeFOV模型变体在VGG-16 'fc6'层采用了比例 r=2 的多孔卷积,有显著的性能提升。
关于实现,有两种方法来有效的执行空洞卷积。
-
第一个是通过插入空洞(零)来隐含地对滤波器进行上采样,或等效稀疏地对输入特征图进行采样。通过向im2col函数(从多通道特征图中提取矢量化块)添加稀疏采样底层特征图实现了这一点。
-
第二种方法,用一个等于空洞卷积率\( r \)等效的因子对输入特征图下采样,对于每一个r×r的移位,都对其进行去交织以产生\( r^2 \)大小的的分辨率映射。然后将标准卷积应用于这些中间特征图,并隔行扫描生成原始图像分辨率。通过将多孔卷积变换为常规卷积,可以使用现成的高度优化的卷积方法。我们已经在TensorFlow框架中实现了第二种方法。
【ASPP】
DCNN识别多尺度物体的能力很强,只需使用含有多尺度物体的数据集进行训练。不过,明确地考虑对象大小可以提高DCNN成功处理不同大小对象的能力。
尝试了两种方法来处理语义分割中的尺度变换:
第一种方法相当于标准多尺度处理。将原始图像放缩为不同的大小,分别输入到使用相同参数的多个DCNN中,融合score map得到预测结果。为了产生最终的结果,对并行DCNN分支特征图进行双线性插值使其恢复到一定的分辨率,并融合它们,在不同尺度上获取每个位置的最大响应。在训练和测试期间都这样做。多尺度处理显著提高了性能,但代价是需要在输入图像的多个尺度上对所有DCNN层计算特征响应(计算量大)。
第二种方法受SPPNet中SPP模块的的启发,它指出在任意尺度的区域,可以用从单个尺度图像中进行重采样提取的卷积特征进行准确有效地分类。我们用不同采样率的多个并行的空洞卷积实现了他们的方案的一个变体。并行的采用多个采样率的空洞卷积提取特征,再将特征融合,类似于空间金字塔结构。所提出的“多孔空间金字塔池化”(DeepLab-ASPP)方法泛化了DeepLab-LargeFOV变体,如下图所示。

【利用全连接分支条件场进行结构化预测】
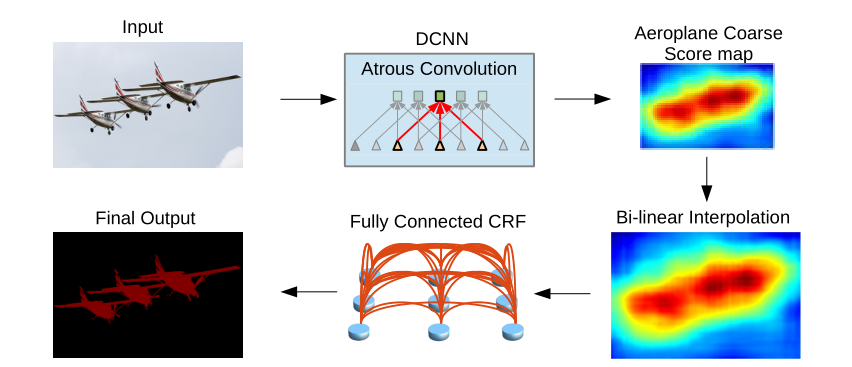
定位精度与分类性能在DCNN中似乎是必须要加以权衡的:具有多个最大池化层的深层模型在分类任务中被证明是非常成功的,然而顶层节点具有的不变性和很大的感受野导致只能产生模糊的响应。如下图所示,DCNN得分图可以预测物体的存在和粗略位置,但不能真正描绘其边界
以前的工作从两个方向来解决这个定位的挑战。
-
第一种方法是利用卷积网络中多层信息,以更好地估计物体边界(FCN系)。
-
第二个是采用超像素表示,将定位任务委托给低层分割方法。
我们通过耦合DCNN的识别能力和全连接的CRF的细粒度定位精度来寻求替代方向,并且在解决定位挑战方面非常成功,产生了精确的语义分割结果并在一定程度上恢复物体边界细节,远远超出现有方法。
条件随机场(CRF)传统上被用于平滑分割图噪声。一般模型耦合邻近节点,有利于对空间邻近像素分配相同的标签。定性地讲,这些短距离CRF的主要功能是减弱基于局部手工设计特征的弱分类器的错误预测。
现代DCNN体系结构得到的score map和对语义标签的预测,与这些弱分类器相比是有本质的不同的。如图5所示,score map通常相当平滑并产生均匀的分类结果。在这个情况下,使用短距离的CRFs可能是不好的,因为我们的目标应该是恢复详细的局部结构,而不是进一步平滑它。使用局部CRF关联的反差灵敏势能函数可以潜在地改善定位,但仍然错过细小的结构,还需要解决高昂的离散优化问题。
为了克服短距离CRF的这些限制,我们结合全连接的CRF模型。模型采用能量函数如下:
\(\begin{align} E(x) = \sum_{i} \theta_{i} (x_i) + \sum_{ij} \theta_{ij} (x_i, x_j)\end{align}\)
其中\(x \)是像素的标签,用于单点势能\(\theta_{i}(x_i) = -\log P(x_i) \),而\( P(x_i)\)是DCNN对像素\(i \)处分配标签的概率。
成对势能具有相同的有效推断的形式,即当连接所有图像像素对\( i, j\) , 时。具体如Dense CRF,使用以下表达式:
\(\begin{align} \theta_{ij}(x_i, x_j) = \mu (x_i, x_j)[\omega_1 \exp(-\frac{||p_i – p_j||^2}{2\sigma_{\alpha}^{2}}) – \frac{||I_i – I_j||^2}{2\sigma_{\beta}^2} + \omega_2 \exp(-\frac{||p_i – p_j||^2}{2\sigma_{\gamma}^2})]\end{align}\)
其中\(\mu(x_i, x_j) = 1 \),如果\( x_i \neq x_j\);否则\( x_i = x_j\)为零,如在POTTS模型中,意味着只有不同标签的节点会被惩罚。
表达式的剩下部分使用两个不同特征空间中的高斯内核;
第一个“双边”内核取决于像素位置( 记为 \( P \) )和RGB颜色( 记为 \( I \) )
第二个内核仅依赖于像素位置。超参数\(\sigma_\alpha, \sigma_\beta, \sigma_\gamma \)控制高斯核的尺度。
第一个内核迫使颜色相似、位置相近的像素具有相似的标签,第二个内核是为了在迫使结果平滑时能够考虑到空间相似度。
关键的是,这个模型适合于进行近似概率推理。在全分解的平均场近似值\(\begin{align} \prod_{i} b_i(x_i)\end{align}\)下的消息传递更新可以表示为双边空间中的高斯卷积。高维滤波算法显著加速了这种计算,使得算法在实际中非常快,在PASCAL VOC图像上使用Dense CRF的开源方法,平均要少于0.5秒
【复现】
待补充
【总结】
DeepLabv2将空洞卷积应用到密集的特征提取,进一步的提出了空洞卷积金字塔池化结构、并将DCNN和CRF融合用于细化分割结果。实验表明,DeepLabv2在多个数据集上表现优异,有着不错的分割性能。